
솔직히 말해봅시다.
요즘 "Chat with Code"라는 타이틀 달고 나오는 서비스들, 써보셨나요?
장난감 수준입니다.
파일 몇 개 업로드하면 대충 답변해주는데, 조금만 뎁스가 깊어지면 바로 헛소리(Hallucination)를 내뱉죠.
왜 그럴까요?
개발자들조차 RAG(Retrieval-Augmented Generation)를 '단순 검색기'로 착각하기 때문입니다.
텍스트를 500자 단위로 뚝뚝 끊어서(Chunking) 벡터 DB에 넣고, 유사도 검색해서 LLM에 던져주는 게 전부니까요.
코드는 소설책이 아닙니다.
함수 중간이 잘려 나간 텍스트 조각을 보고 문맥을 이해할 수 있는 모델은 없습니다.
그건 그냥 GPU 비용 태워서 만드는 난수표일 뿐이죠.
제가 오늘 가져온 이 프로젝트, RepoReaper는 다릅니다.
이건 단순한 툴 소개가 아닙니다.
"LLM으로 코드를 분석하려면 이렇게 해야 한다"는 엔지니어링 정석을 보여주는 사례라서 들고 왔습니다.
이 친구들이 접근하는 방식을 보면, 진짜 '선수'가 설계했다는 느낌이 팍 옵니다.
1. 텍스트가 아니라 '구조(AST)'를 봅니다.
보통 RAG 구현할 때 가장 많이 하는 실수가 뭘까요?
Character 단위로 끊는 겁니다.
하지만 이 프로젝트는 AST(Abstract Syntax Tree)를 파싱합니다.
쉽게 말해 코드를 글자가 아니라, 클래스와 메서드라는 '논리적 덩어리'로 인식한다는 겁니다.
클래스가 너무 커서 메서드 단위로 잘라야 할 때도, 그냥 자르지 않습니다.
부모 클래스의 정의와 Docstring을 자식 청크에 강제로 주입합니다.
이게 핵심입니다.
LLM에게 '어떻게(How)'만 보여주는 게 아니라 '왜(Why)'를 같이 보여주는 거죠.
이런 전처리 없이 최신 모델 쓴다고 성능이 좋아질까요?
절대 아닙니다.
데이터 전처리가 쓰레기면, 결과도 쓰레기입니다.
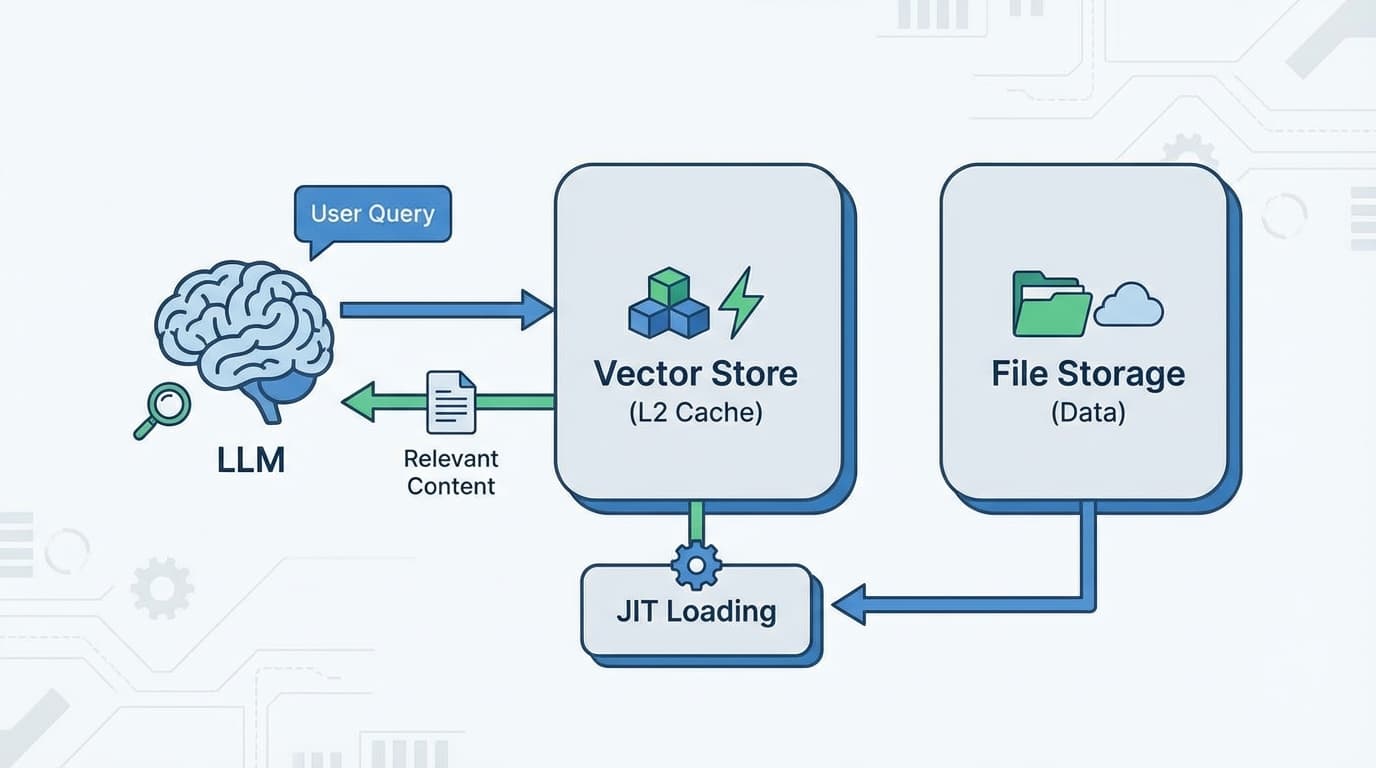
2. RAG를 '정적 도서관'이 아니라 'CPU 캐시'로 씁니다.
많은 분들이 저장소 전체를 벡터 DB에 몽땅 때려 박으려고 합니다.
그거 인덱싱하는 비용이랑 시간은 누가 감당합니까?
이 프로젝트는 JIT(Just-In-Time) 방식을 씁니다.
처음엔 가볍게 전체 구조(심볼 맵)만 훑습니다.
그리고 사용자가 질문을 던지면, 그제야 필요한 파일만 가져옵니다.
마치 CPU가 L1, L2 캐시를 운용하듯이,
벡터 스토어를 LLM의 동적 캐시(Dynamic Cache)로 활용하는 겁니다.
중요한 파일 10~20개만 미리 '웜업(Warm-up)' 해두고, 나머지는 필요할 때 읽습니다.
이게 바로 비용 효율화입니다.
무식하게 다 읽어들이는 게 아니라, 필요한 만큼만 자원(Resource)을 쓰는 것.
현업에서 가장 중요한 역량입니다.
3. 모르면 "모른다"고 하고 찾아봅니다.
기존 챗봇들은 문맥이 부족하면 그냥 말을 지어냅니다.
하지만 이 시스템은 ReAct(Reasoning + Acting) 루프를 돕니다.
사용자 질문이 들어왔는데, 캐시(RAG)에 정보가 없다?
그럼 LLM이 스스로 판단해서 명령을 내립니다.
"잠깐, 저 파일 좀 읽어와야겠는데?"
이렇게 스스로 GitHub API를 호출해서 파일을 읽어오고, 인덱싱한 뒤에 다시 답변을 생성합니다.
시니어 개발자가 코드 보다가 모르는 함수 나오면 눌러서 확인하는 과정이랑 똑같습니다.
이게 진짜 에이전트(Agent)입니다.
4. 뼈 때리는 조언
이 프로젝트는 Python의 와 를 써서 I/O 처리량도 극대화했습니다.
파싱, AST 추출, 임베딩이 동시에 비동기로 돌아갑니다.
제가 주니어 분들한테 항상 하는 말이 있습니다.
"LLM API 호출하는 건 코딩이 아니다."
진짜 실력은 API 호출 전후의 파이프라인을 어떻게 설계하느냐에서 나옵니다.
RepoReaper는 그 트레이드오프(Trade-off)를 아주 영리하게 가져갔습니다.
정확도를 위해 AST를 쓰고, 비용을 아끼기 위해 JIT를 썼습니다.
여러분이 지금 만들고 있는 AI 서비스,
그저 최신 모델에 의존하고 있지는 않나요?
아니면 이렇게 데이터의 구조와 시스템의 효율을 고민하고 있나요?
코드는 거짓말하지 않습니다.
설계가 허술하면, AI도 멍청해질 뿐입니다.
오늘 당장 여러분의 RAG 파이프라인을 다시 열어보세요.
텍스트를 그냥 뚝뚝 끊어서 넣고 있었다면,
그건 생성형 AI가 아니라 그냥 엑셀 찾기 놀이를 하고 계신 겁니다.



![[브루킹스 연구소] 50개국 현장 조사: AI가 인간의 뇌를 '퇴화'시킨다는 결정적 증거](/_next/image?url=https%3A%2F%2Fstorage.googleapis.com%2Fpoooling-blog%2Fblog-images%2F2026%2F02%2F02%2F2620_b8418316.png&w=3840&q=75)