
"지연 시간(Latency) 500ms."
이 숫자가 무엇을 의미하는지 아십니까?
사용자가 여러분이 만든 음성 AI를 보며 "멍청하다"고 느끼기 시작하는 임계점입니다.
현업에서 음성 인터페이스(Voice Agent)를 개발해 본 분들은 아실 겁니다.
ASR(음성 인식) 거치고, LLM(추론) 태우고, TTS(음성 합성)까지 돌아서 나오는데 1초, 2초...
그 어색한 정적(Silence)을 메우려고 "잠시만 기다려주세요" 같은 무의미한 필러(Filler) 단어만 남발하죠.
솔직히 말해, 부끄러운 수준이었습니다.
그런데 최근 엔비디아가 꽤 흥미로운 물건을 허깅페이스(Hugging Face)에 조용히 풀었습니다.
단순히 모델 하나 던져준 게 아닙니다.
'실시간(Real-time)'의 정의를 다시 쓰겠다는 선전포고나 다름없습니다.
제가 벤치마크 문서를 뜯어보다가 가장 먼저 눈에 꽂힌 숫자가 있습니다.
24ms.
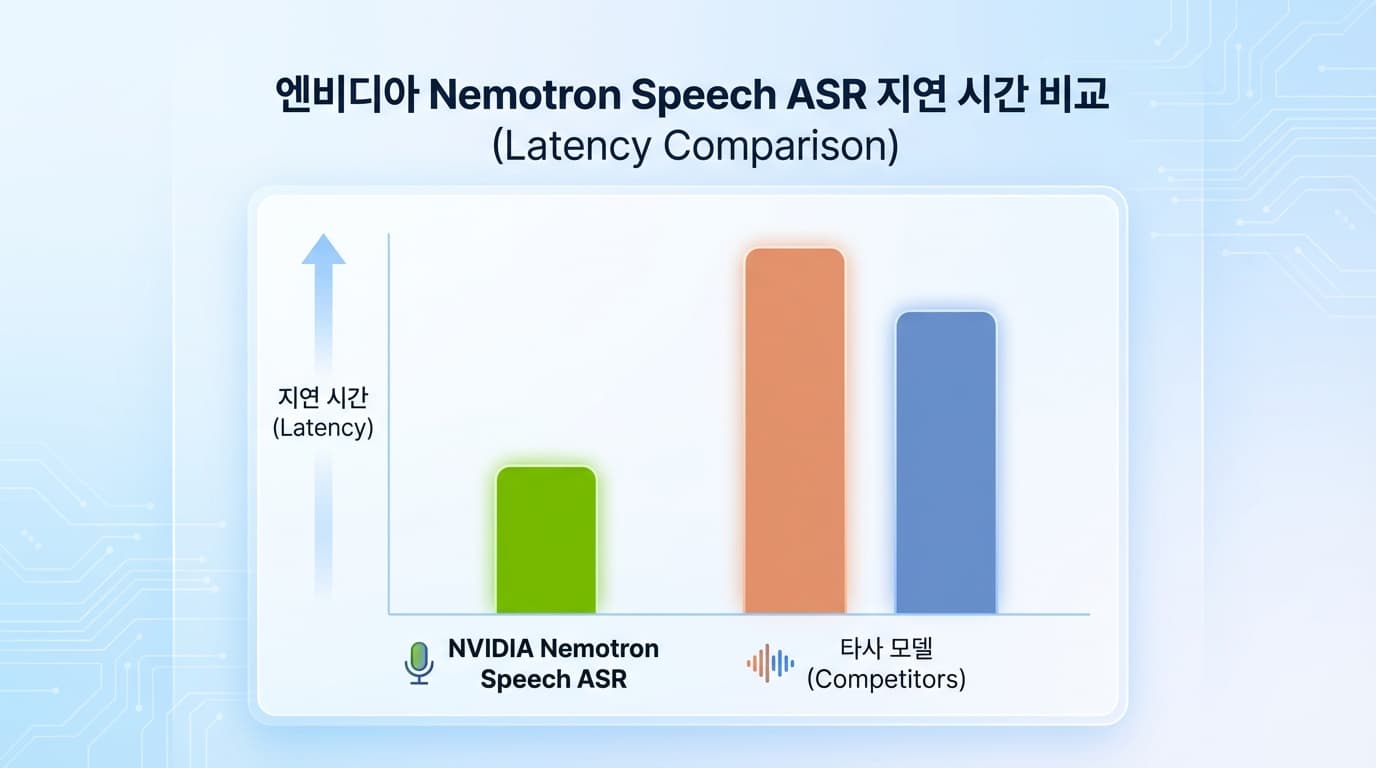
기존에 우리가 "빠르다"고 칭송하던 OpenAI의 Whisper 모델 기억하십니까?
Whisper의 평균 레이턴시는 600ms에서 800ms 사이입니다.
정확도는 좋지만, 실시간 대화용으로는 구조적인 한계가 명확했죠.
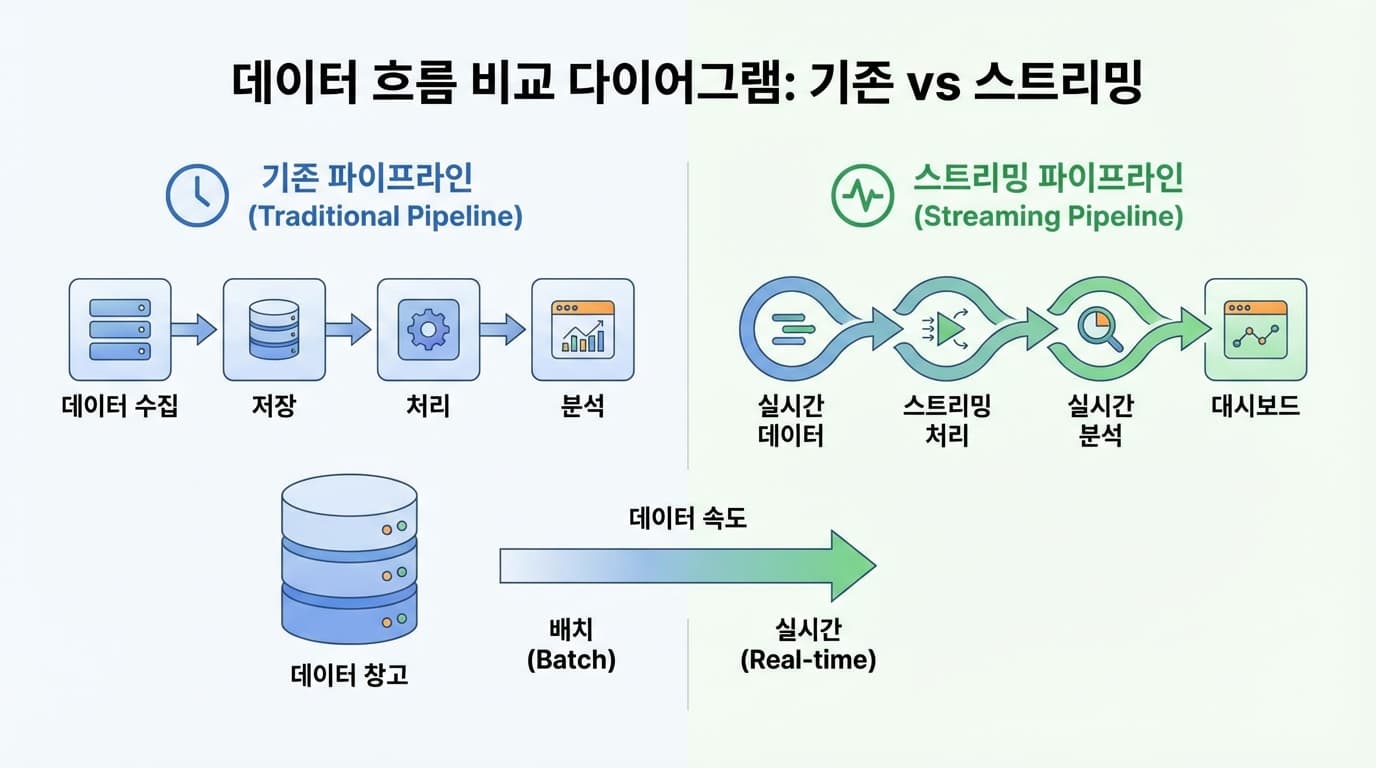
Whisper는 기본적으로 배치 처리(Batch Processing)를 위해 설계됐으니까요.
오디오 청크(Chunk)가 찰 때까지 기다렸다가 한 번에 처리하는 방식입니다.
당연히 느릴 수밖에 없습니다.
반면 이번에 공개된 Nemotron Speech ASR은 아키텍처가 완전히 다릅니다.
캐시 인식 스트리밍(Cache-aware Streaming) 방식을 도입했습니다.
기다리지 않습니다. 들어오는 즉시 처리합니다.
그 결과가 바로 24ms 미만의 전사(Transcription) 속도입니다.
이건 인간이 인지할 수 없는 수준의 속도입니다.
단순히 "말을 빨리 알아듣는다" 수준이 아닙니다.
전체 파이프라인의 병목(Bottleneck) 중 가장 큰 덩어리가 사라졌다는 뜻입니다.
하지만 음성 인식만 빠르다고 해결될 문제는 아닙니다.
뇌가 느리면 귀가 밝아봤자 소용없죠.
엔비디아는 이 ASR 모델과 짝을 이룰 두 가지 무기를 더 준비했습니다.
- Nemotron 3 Nano LLM
- Magpie TTS (프리뷰)
Nemotron 3 Nano는 거대하고 무거운 모델이 아닙니다.
Throughput(처리량)과 Latency 최적화에 목숨 건 모델입니다.
긴 컨텍스트를 유지하면서도 멀티 턴(Multi-turn) 대화에서 동급 최강의 성능을 뽑아냅니다.
여기에 곧 정식 출시될 Magpie TTS까지 붙이면?
입력부터 출력까지(End-to-End) 끊김 없는 스트리밍 파이프라인이 완성됩니다.
이게 왜 중요할까요?
지금까지 우리는 클라우드 API 호출 비용과 네트워크 레이턴시 사이에서 줄타기했습니다.
SaaS 형태의 폐쇄형 모델(Proprietary Model)을 쓰면 편하긴 합니다.
하지만 내 데이터가 외부로 나가는 보안 문제, 그리고 통제할 수 없는 네트워크 지연 시간은 늘 골칫거리였죠.
이번에 공개된 모델들은 NVIDIA Permissive Open-Model License를 따릅니다.
상업적 이용 가능? OK.
파생 모델 제작? OK.
즉, 여러분의 VPC(가상 사설 클라우드) 안이나 온프레미스 장비에 직접 띄울 수 있다는 겁니다.
TCO(총 소유 비용) 관점에서도 훨씬 합리적입니다.
비싼 API 토큰 비용 태우는 대신, 정해진 GPU 리소스 안에서 최대 효율을 뽑아낼 수 있으니까요.
물론, "오픈 소스는 성능이 떨어진다"는 편견이 있을 수 있습니다.
하지만 WER(단어 오류율) 지표를 보면 상용 모델과 대등하거나 오히려 더 낫습니다.
특히 노이즈가 심한 환경에서의 인식률은 이전 세대 오픈 모델들을 압도합니다.
이제 핑계 댈 수 없습니다.
하드웨어 탓, 모델 탓 하던 시절은 지났습니다.
집에 놀고 있는 RTX 5090이나, 회사 서버실 구석에 박혀있는 DGX 장비가 있다면 당장 시도해 보세요.
관련 코드는 깃허브에 다 올라와 있습니다.
Pipecat 라이브러리를 활용하면 이 복잡한 스트리밍 파이프라인을 생각보다 쉽게 구축할 수 있습니다.

개발자라면 단순 '사용자'에 머물지 마십시오.
무거운 라이브러리 import 해서 API 키만 갈아 끼우는 건 누구나 합니다.
직접 모델을 올리고, 오디오 청크 사이즈를 조절해가며 튜닝해 보십시오.
새벽에 서버 로그 보다가 레이턴시가 튀어서 막막해질 때가 있을 겁니다.
어디가 병목인지 모르겠으면 로그 들고 찾아오세요.
디버깅 포인트 정도는 짚어드릴 테니.
진짜 '대화'가 되는 AI는 이제부터 시작입니다.



