
현업에서 AI 인프라를 설계하다 보면 가장 답답한 순간이 있습니다. 바로 모든 트래픽을 무지성으로 GPT-4나 Claude 3.5 Sonnet 같은 SOTA(State-of-the-Art) 모델에 태우는 경우입니다. 물론 성능은 확실합니다. 하지만 비즈니스 관점에서 보면 이건 자살행위나 다름없습니다. 간단한 인사말이나 요약 요청 처리에도 건당 수십 원의 비용과 수백 밀리초의 레이턴시(Latency)를 태우는 꼴이기 때문입니다. 서비스 초기에는 티가 안 나겠지만, 트래픽이 조금만 늘어도 TCO(총 소유 비용)가 기하급수적으로 폭발하여 감당할 수 없는 지경에 이릅니다.
저는 삼성전자에서 SSD 펌웨어를 최적화하던 시절부터 '적재적소'의 원칙을 뼈저리게 배웠습니다. 데이터의 성격에 따라 SLC, MLC, TLC 낸드 중 어디에 쓸지를 결정하는 로직 하나가 전체 스토리지의 수명과 성능을 결정짓습니다. LLM 서비스도 마찬가지입니다. 모든 요청을 가장 비싼 모델이 처리할 필요는 없습니다. 쿼리의 난이도와 중요도에 따라 7B 사이즈의 경량 모델이 처리할지, 70B 이상의 거대 모델이 처리할지를 판단해 주는 '게이트키퍼'가 필요합니다. 우리는 이것을 'LLM 라우팅(Routing)'이라고 부릅니다.
최근 공개된 오픈소스 라이브러리인 'LLMRouter'는 이러한 고민에 대한 꽤 진지한 대답을 내놓았습니다. 단순히 규칙 기반(Rule-based)으로 모델을 분기하는 수준을 넘어섰습니다. 이 라이브러리는 쿼리의 복잡도, 예상 비용, 요구 성능을 종합적으로 판단하여 최적의 모델로 연결해 줍니다. 흥미로운 점은 라우팅 결정 자체를 위해 머신러닝 알고리즘을 사용한다는 것입니다. KNN, SVM, MLP(다층 퍼셉트론) 같은 고전적인 분류기부터, Matrix Factorization이나 BERT 기반의 라우팅까지 총 16개 이상의 전략을 지원합니다.
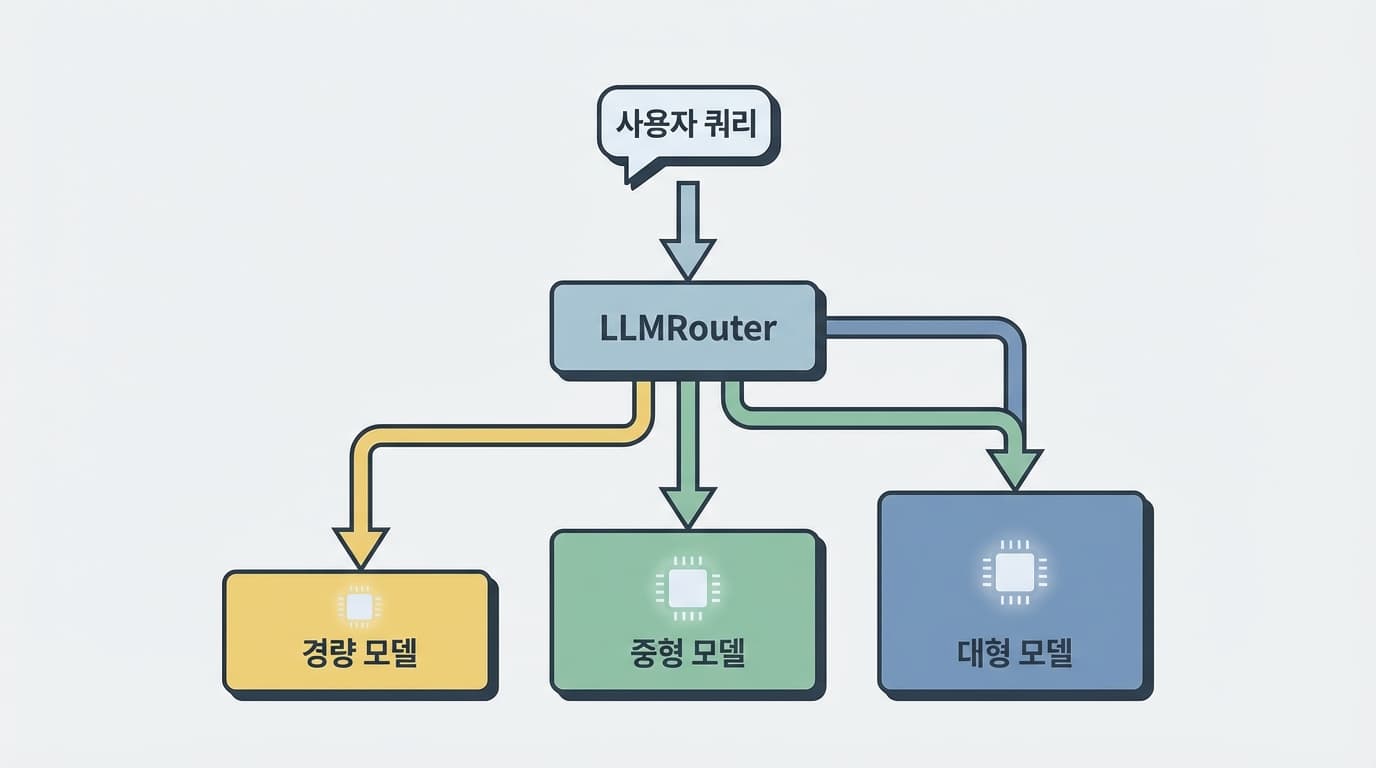
이 라이브러리의 핵심은 '다양성'과 '확장성'에 있습니다. 단순히 한 번의 질의응답을 처리하는 싱글 라운드(Single-round) 라우터뿐만 아니라, 대화의 맥락을 파악해야 하는 멀티 라운드(Multi-round), 더 나아가 에이전트 시스템을 위한 에이전틱(Agentic) 라우터까지 포함하고 있습니다. 엔비디아에서 데이터센터 시스템을 다루면서 늘 고민하는 부분이 바로 이 '워크로드의 다양성'입니다. 모든 워크로드가 균일하지 않기 때문에, 상황에 맞춰 유연하게 대처할 수 있는 도구가 필수적입니다. LLMRouter는 바로 그 지점을 파고들었습니다.
특히 주목할 만한 기능은 데이터 생성 파이프라인입니다. 라우터를 학습시키려면 "이런 질문은 이 모델이 잘한다"라는 정답 데이터셋이 필요합니다. 하지만 현업에서 이런 데이터를 구축하는 건 막막한 일입니다. LLMRouter는 11개의 벤치마크 데이터셋을 기반으로 API를 자동 호출하고 평가하여, 라우터 학습을 위한 데이터를 생성하는 전체 파이프라인을 제공합니다. 이는 개발자가 맨땅에 헤딩하지 않고도, 자신만의 라우팅 로직을 빠르게 구축하고 실험해 볼 수 있게 해 줍니다.
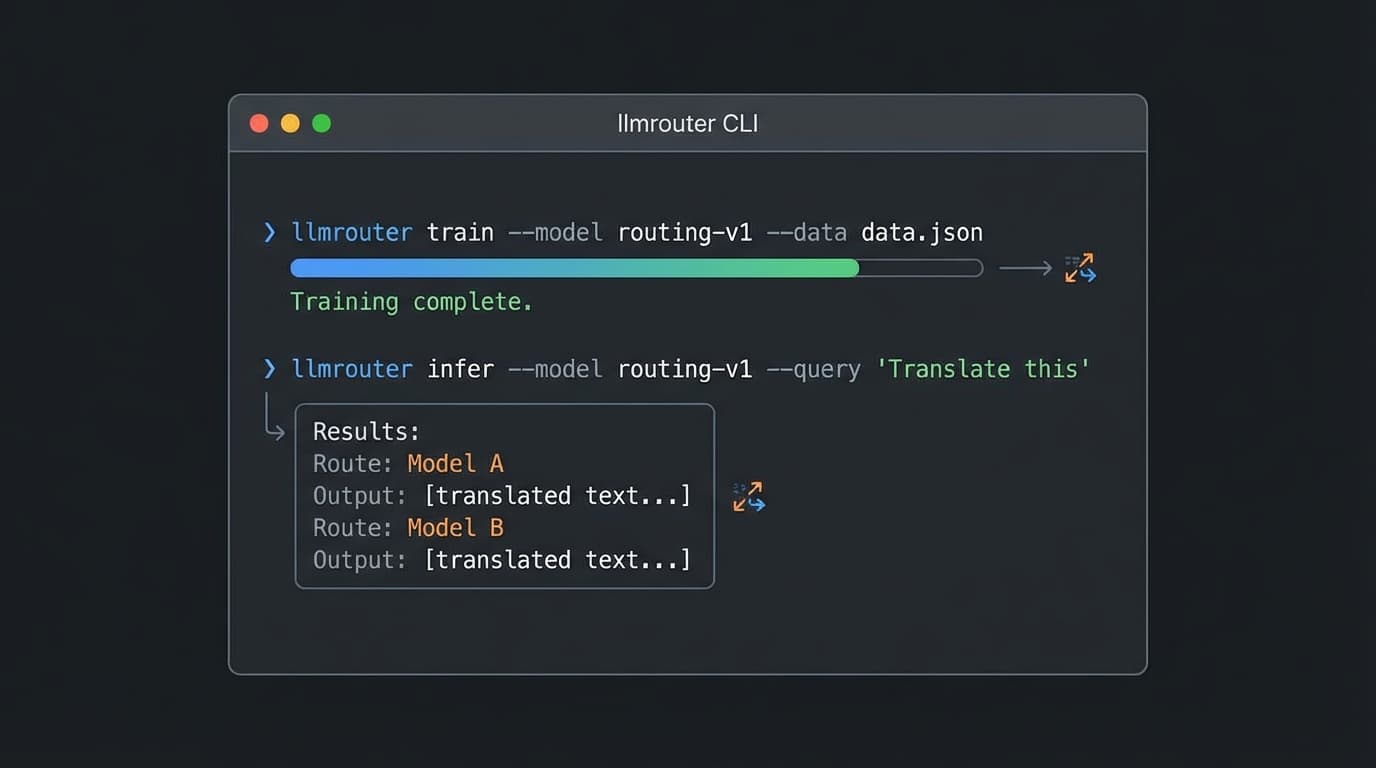
설치와 사용법도 꽤 직관적입니다. pip install llmrouter-lib 명령어로 간단히 설치할 수 있으며, NVIDIA, OpenAI, Anthropic 등 다양한 공급자의 API 키를 딕셔너리 형태로 관리할 수 있습니다. CLI(Command Line Interface)를 통해 학습과 추론, 그리고 Gradio 기반의 대화형 UI까지 띄울 수 있어, 백엔드 엔지니어뿐만 아니라 ML 리서처들도 빠르게 프로토타이핑을 해볼 수 있는 구조입니다. 코드를 뜯어보면 단순한 래퍼(Wrapper)가 아니라, 성능 최적화를 위해 꽤 공을 들인 흔적이 보입니다.
물론 이 라이브러리 하나 깐다고 해서 모든 문제가 해결되지는 않습니다. 라우터 모델 자체의 오버헤드(Overhead)도 고려해야 하고, 라우팅 실패 시의 폴백(Fallback) 전략도 세워야 합니다. 라우터가 "이건 싼 모델로도 돼"라고 잘못 판단해서 엉뚱한 답변이 나가면, 사용자 경험은 박살 납니다. 반대로 너무 보수적으로 라우팅 하면 비용 절감 효과가 미미할 것입니다. 결국 우리 서비스의 쿼리 패턴을 정확히 분석하고, 적절한 학습 데이터를 통해 라우터를 튜닝하는 '엔지니어링'의 영역은 여전히 남아 있습니다.
지금 여러분의 서비스 아키텍처를 점검해 보십시오. 단순히 무거운 라이브러리를 가져다가 API만 호출하고 있지는 않습니까? 효율성은 엔지니어의 자존심입니다. 새벽 3시, 갑작스러운 트래픽 스파이크에도 서버가 뻗지 않고, 청구서에 찍힌 금액을 보고 경영진이 안도의 한숨을 내쉬게 만드는 것. 그것이 진짜 실력입니다. LLM 라우팅은 이제 선택이 아니라 생존을 위한 필수 조건이 되어가고 있습니다. 당장 LLMRouter를 클론 받아서 테스트해보세요. 디버깅하다 막히면 언제든 질문 남기셔도 좋습니다. 그 치열한 고민의 과정이 여러분을 단순한 '코더'에서 진정한 '아키텍트'로 만들어줄 테니까요.



