
회의실에 들어가면 화면에 빙글빙글 돌아가는 로딩 바만 띄워놓고 식은땀을 흘리는 주니어들을 자주 봅니다. "데이터가 너무 많아서 쿼리가 늦습니다"라는 변명은 통하지 않습니다. 사용자는, 특히 의사결정권자는 당신의 DB 구조나 네트워크 레이턴시 사정 따위는 궁금해하지 않습니다. 그들이 원하는 건 즉각적인 현황 파악과 인사이트입니다. 핀테크에서 수백만 건의 결제 트랜잭션을 처리하다 보면 시각화는 단순한 디자인 영역이 아니라 생존을 위한 엔지니어링임을 뼈저리게 느끼게 됩니다. 오늘은 2012년 전 세계 상선 데이터를 기반으로 구축된 'Shipmap.org' 사례를 통해, 대용량 데이터를 어떻게 효과적으로 시각화하고 비즈니스 임팩트를 만들어내는지 분석해 보겠습니다. 단순히 "지도가 예쁘다"고 감탄하고 끝낼 거라면 지금 이 창을 닫으셔도 좋습니다.
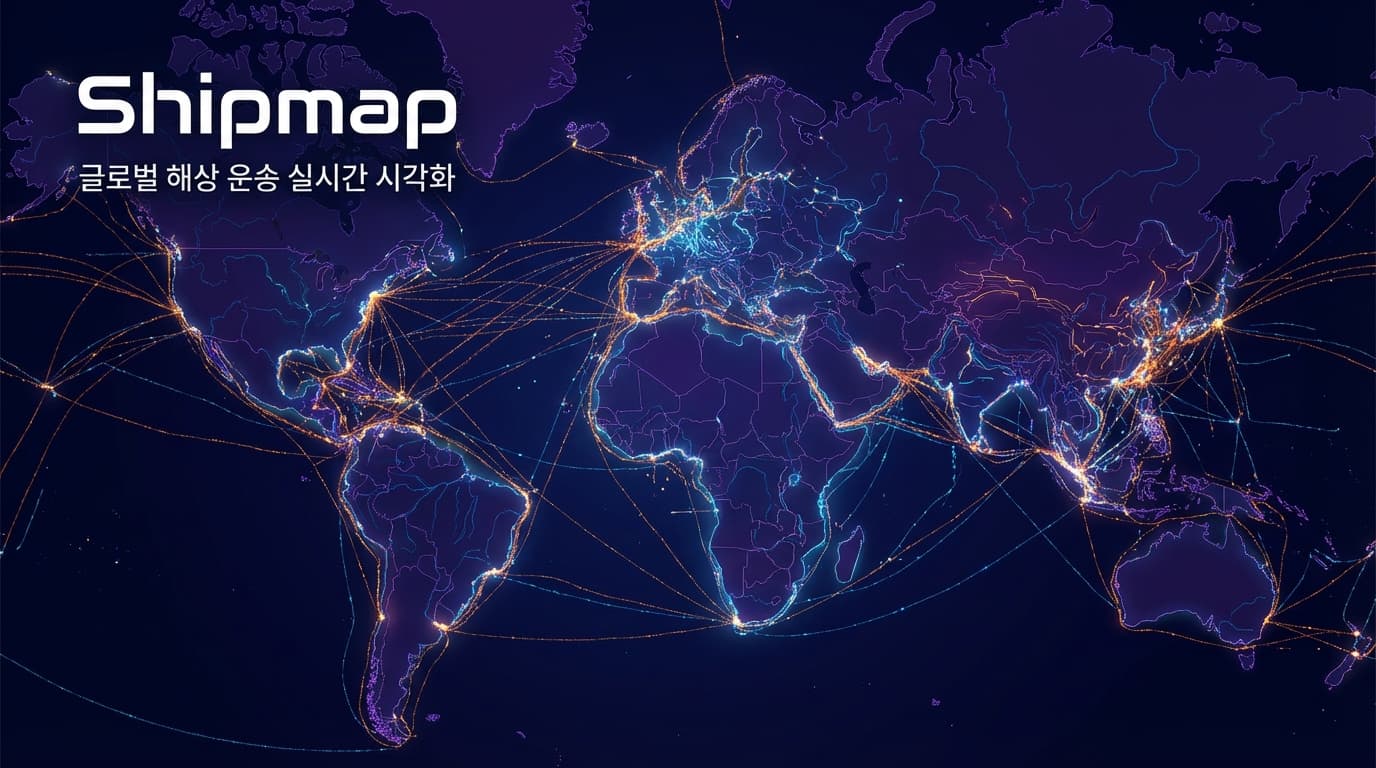
우선 이 프로젝트가 다루고 있는 데이터의 스케일과 이를 처리하는 방식을 주목해야 합니다. Shipmap은 exactEarth의 AIS(선박 자동 식별 장치) 데이터와 Clarksons의 선박 제원 데이터를 결합하여 수십억 개의 위치 포인트를 다룹니다. 초보 기획자들이 흔히 저지르는 실수가 이 정도 데이터를 DOM 요소로 직접 렌더링하려다 브라우저를 터뜨리는 것입니다. 이 프로젝트는 Kiln과 UCL 에너지 연구소(UCL EI)가 협업하여 WebGL 기술을 채택했습니다. 수심 데이터(GEBCO_2014 Grid)를 베이스맵으로 깔고, 그 위에 수만 척의 선박 움직임을 GPU 가속을 통해 부드럽게 그려냅니다. 이는 기술적 선택이 아니라 필수적인 생존 전략입니다. 여러분이 대시보드를 기획할 때 데이터 로우(row) 수가 10만 단위를 넘어간다면, 일반적인 차트 라이브러리가 아니라 렌더링 최적화 기술부터 검토해야 한다는 뜻입니다.
데이터 시각화의 본질은 '예쁜 그림'이 아니라 '정보의 구조화'에 있습니다. Shipmap은 컨테이너선, 건화물선(Dry bulk), 유조선(Tanker), 가스선, 자동차 운반선 등 5가지 카테고리로 선박을 분류하고 필터링 기능을 제공합니다. 여기서 중요한 건 단순히 배의 위치만 보여주는 것이 아니라, 각 선박 유형에 맞는 핵심 지표(Key Metrics)를 산출했다는 점입니다. 컨테이너선은 슬롯 수, 가스선은 입방미터(m³), 벌크선은 톤수(kt)로 단위를 구분하여 상단에 실시간 카운터로 보여줍니다. 또한, 단순히 이동 경로만 보여주는 데 그치지 않고, IMO(국제해사기구) 연구 방식을 적용해 CO2 배출량을 계산하여 시각화했습니다. 이는 데이터를 단순 나열하는 것을 넘어, "이 물동량이 환경에 어떤 영향을 미치는가?"라는 비즈니스적 질문에 대한 답을 데이터로 제시하는 훌륭한 레퍼런스입니다. 기획자라면 "무엇을 보여줄까?"가 아니라 "어떤 문제를 해결할 지표인가?"를 먼저 고민해야 합니다.
완벽한 데이터는 없다는 것을 인정하고 이를 투명하게 공개하는 태도 역시 배워야 합니다. 이 시각화 지도를 자세히 보면 가끔 선박이 육지를 가로질러 이동하는 '아티팩트(Artifact)' 현상이 발견됩니다. 이는 운하를 통과하거나 데이터 수신이 끊긴 두 지점 사이를 애니메이션으로 보간(Interpolation)하는 과정에서 발생하는 기술적 한계입니다. 또한 1월부터 4월까지의 데이터가 불완전하다는 사실도 명시되어 있습니다. 많은 주니어들이 이런 결함을 숨기려다 데이터 전체의 신뢰도를 떨어뜨립니다. 데이터 정합성이 100%가 아니라면, 어디가 비어있고 왜 그런 현상이 발생하는지를 명확히 밝히는 것이 오히려 사용자의 신뢰를 얻는 길입니다. "데이터가 이상한데요?"라는 지적을 받기 전에 "이 구간은 보간 처리된 데이터입니다"라고 먼저 말할 수 있어야 프로덕트의 주도권을 쥘 수 있습니다.
결국 성공적인 데이터 프로덕트는 강력한 백엔드 엔지니어링과 명확한 기획 의도가 만나는 지점에서 탄생합니다. Shipmap은 런던의 디자인 스튜디오와 대학 연구소가 협력하여 복잡한 해운 데이터를 누구나 이해할 수 있는 직관적인 형태로 가공해 냈습니다. 여러분이 지금 만들고 있는 어드민 대시보드나 리포트 시스템을 돌아보십시오. 사용자가 원하는 정보를 얻기 위해 엑셀을 다운로드하고 피벗 테이블을 다시 돌려야 한다면, 그건 실패한 프로덕트입니다. 데이터 드리븐은 말로 하는 것이 아닙니다. 수집된 데이터를 어떤 기술로 렌더링하고, 어떤 지표로 가공하여 의사결정을 도울 것인지 설계하는 것, 그것이 PO와 개발자가 해야 할 진짜 업무입니다. 감으로 일하지 마십시오. 보여지는 데이터만이 설득력을 가집니다.



