
솔직히 말해봅시다. 장애가 터지면 가장 먼저 하는 일이 뭡니까? 로그를 보는 게 아니라 '누구 탓인지' 정하는 것 아닙니까? 백엔드 개발자는 "코드 배포한 지 3일 지났는데 아무 문제 없었어요"라고 하고, 인프라 엔지니어는 "DB CPU가 100% 쳤으니 쿼리가 문제죠"라며 서로 핑퐁을 칩니다. 이 지루한 공방전이 오가는 사이, 서비스의 가용성(Availability)은 떨어지고 우리네 수명도 같이 줄어듭니다.
실리콘밸리에서 Staff SRE로 일하며 수없이 겪은 패턴입니다. 우리는 흔히 애플리케이션은 APM(Application Performance Monitoring)으로, 데이터베이스는 AWS RDS 콘솔이나 별도의 전문 도구로 모니터링합니다. 트래픽이 적을 땐 이 방식도 통합니다. 사람이 눈으로 대시보드 두 개를 번갈아 보며 타임스탬프를 맞추면 되니까요. 하지만 트래픽이 초당 수만 건을 넘어가고 마이크로서비스(MSA)가 복잡하게 얽히기 시작하면 이 '분리된 관측'은 재앙이 됩니다.
문제의 핵심은 도구가 아닙니다. 우리의 정신 모델(Mental Model)입니다. 우리는 데이터베이스를 자꾸만 '외부 의존성(External Dependency)'으로 취급하려 합니다. 마치 써드파티 API처럼요. 하지만 현실은 냉혹합니다. Postgres는 외부 시스템이 아니라, 여러분이 짠 애플리케이션 코드의 상태(State)를 저장하는 컴포넌트일 뿐입니다. DB의 부하는 하늘에서 뚝 떨어지는 게 아니라, ORM이 생성한 쿼리, 특정 유저의 행동, 잘못 설계된 루프 문에서 비롯됩니다.
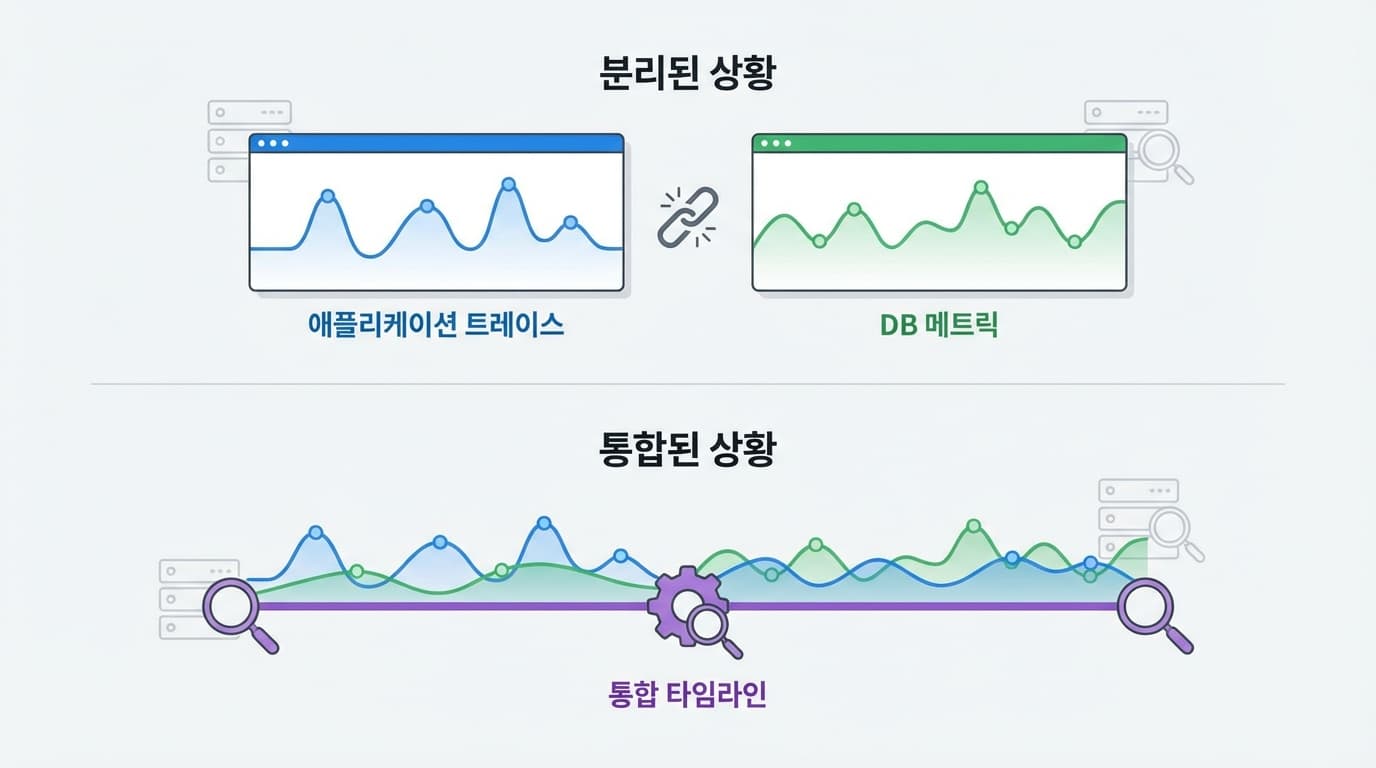
최근 Base14에서 내놓은 pgX 같은 도구가 주목받는 이유도 여기에 있습니다. 단순히 DB 메트릭을 더 깊게 보여주는 것(Depth)이 아니라, 애플리케이션 코드의 문맥(Context) 안에서 DB를 보여주기 때문입니다. 쿼리 지연이 발생했을 때, 그게 단순히 '느린 쿼리'인 것과 '특정 API 엔드포인트에서 호출된, 락(Lock) 대기 중인 쿼리'라는 정보는 하늘과 땅 차이입니다. 전자는 DBA를 찾게 만들지만, 후자는 당장 해당 코드를 짠 개발자가 롤백을 하든 핫픽스를 하든 액션을 취하게 만듭니다.
제가 팀원들에게 강조하는 '살아남는 모니터링'의 조건은 명확합니다.
- 첫째, 시간축(Time Axis)의 통합입니다. APM의 스파이크와 DB의 스파이크가 같은 그래프 위에 겹쳐 보여야 합니다. "이 시간대에 트래픽이 튀었으니 DB가 느려졌겠지"라고 추측(Guessing)하지 마십시오. 인과관계는 시각적으로 증명되어야 합니다.
- 둘째, 식별자(Identifier)의 공유입니다. 쿼리 로그에 단순히 SQL 문장만 남기지 마십시오. 가능하다면 SQL 주석(Comment)에 Trace ID나 Request ID를 태깅해서 흘려보내십시오. 그래야
SELECT * ...쿼리가 어떤 사용자의 요청에서 시작되었는지 역추적할 수 있습니다. - 셋째, 통합된 저장소(Unified Storage)와 알림입니다. DB CPU 알림 따로, API Latency 알림 따로 받으면, 새벽에 깨어난 몽롱한 정신으로 두 알림의 연관성을 파악하기 어렵습니다. 시스템 전체의 맥락에서 알림이 설계되어야 합니다.
많은 엔지니어들이 불안감을 해소하기 위해 무작정 더 많은 메트릭을 수집하려 합니다. 하지만 문맥 없는 깊이(Depth without Context)는 노이즈일 뿐입니다. 카디널리티(Cardinality)가 높은 데이터는 저장 비용만 늘리고, 정작 사고가 터졌을 때 무엇을 봐야 할지 모르게 만듭니다.
우리는 데이터베이스 전문가(DBA)가 점점 사라지는 시대를 살고 있습니다. 이제 개발자 스스로가 쿼리의 비용을 이해하고, 인프라 엔지니어는 애플리케이션의 흐름을 이해해야 합니다. 도구 사이를 왔다 갔다 하며 '숨은그림찾기'를 하는 건 이제 그만두십시오. 시스템을 하나의 유기체로 바라보고 통합된 관측성(Observability) 환경을 구축하는 것, 그것이 여러분이 새벽 3시에 깨지 않고 아침까지 푹 잘 수 있는 유일한 길입니다.



