

안녕하세요, 10년 차 개발자 김현수입니다.
여러분, 혹시 1GB짜리 로그 파일이나 수십만 줄의 코드를 에디터로 열어본 적 있으신가요?
그때 스크롤을 휙휙 내려도 화면이 바로바로 뜨고, 코드 색상(Syntax Highlighting)이 깨지지 않는 걸 보면 신기하지 않나요?
"그냥 텍스트 파일인데 뭐 어렵겠어?" 싶지만,
사실 이건 엔지니어링 관점에서 보면 기적에 가까운 최적화의 결과물입니다.
오늘은 우리가 매일 쓰는 에디터가 어떻게 그 무거운 텍스트를 '색칠'하는지, 그 뒷단의 점진적(Incremental) 알고리즘 이야기를 해볼까 합니다.
자, 커피 한 잔 내려놓고 편하게 들어보세요.
문법 하이라이팅의 기본 원리
우선 에디터가 코드를 색칠하는 원리부터 아주 간단히 짚고 넘어갈게요.
가장 단순한 형태는 함수형 프로그래밍 구조를 띱니다.
fn syntax(이전_상태, 현재_줄) -> (다음_상태, 색칠_정보)
여기서 '상태(State)'가 핵심입니다.
예를 들어볼까요?
여러분이 /*를 쳐서 주석을 열었다고 칩시다.
그럼 에디터는 "지금부터는 주석 모드야!"라는 상태를 기억해야 다음 줄도, 그다음 줄도 회색으로 칠할 수 있겠죠.
이걸 파서(Parser)의 상태 스택이라고 부릅니다.
무식하게 처리하면 생기는 일
가장 쉬운 구현 방법은 '배치(Batch) 처리'입니다.
파일을 열면 1번째 줄부터 마지막 줄까지 for 문을 돌면서 상태를 계산하는 거죠.
초기 로딩 때는 괜찮습니다.
메모리도 적게 들고요.
하지만 문제는 '편집'할 때 터집니다.
만약 100만 줄짜리 코드의 맨 첫 줄을 수정했다고 상상해 보세요.
에디터는 바뀐 상태를 반영하기 위해 100만 번째 줄까지 다시 계산해야 합니다.
키보드 하나 누를 때마다 O(n)의 시간이 걸리는 셈이죠.
이러면 타이핑할 때마다 렉이 걸려서 개발 못 합니다.
캐싱(Caching): 속도와 메모리의 줄타기
그래서 나온 대안이 '중간 결과 저장'입니다.
모든 줄의 시작 상태(State)를 메모리에 저장해 두는 겁니다.
이를 메모이제이션(Memoization)이라고 하죠.
이렇게 하면 50번째 줄을 화면에 그릴 때, 1번째 줄부터 다시 계산할 필요가 없습니다.
저장된 49번째 줄의 상태를 가져와서 바로 계산하면 되니까요.
속도는 O(n)에서 O(1)에 가깝게 빨라집니다.
그런데 이건 메모리를 엄청나게 잡아먹습니다.
텍스트보다 '상태 정보'가 더 커지는 배보다 배꼽이 더 큰 상황이 올 수도 있어요.
타협점: 체크포인트 시스템
여기서 현업 엔지니어들의 지혜가 발휘됩니다.
"모든 줄을 저장하지 말고, 띄엄띄엄 저장하자."
마치 게임의 세이브 포인트(Save Point) 같은 개념입니다.
모든 줄의 상태를 캐싱하는 게 아니라, 예를 들어 100줄이나 1000줄 간격으로만 상태를 저장하는 겁니다.
이걸 '희소 캐시(Sparse Cache)'라고 부르기도 합니다.
만약 제가 550번째 줄을 보고 싶다면?
500번째 줄에 저장된 상태(세이브 포인트)를 불러와서, 거기서부터 50줄만 빠르게 계산하면 됩니다.
이러면 메모리 사용량도 아끼고, 속도도 챙길 수 있죠.
진짜 문제는 '수정'할 때
하지만 코드는 정적이지 않습니다. 우리가 계속 타이핑을 하잖아요.
이게 골치 아픈 부분입니다.
제가 코드 중간에 /* (주석 시작)을 입력했다고 칩시다.
그럼 그 뒤에 있는 모든 코드가 주석 처리되어야 합니다. 상태가 변한 거죠.
이 파급 효과(Ripple Effect)를 어떻게 처리할까요?
무조건 끝까지 다 다시 계산해야 할까요?
아닙니다. 여기서 '점진적(Incremental) 알고리즘'의 정수가 나옵니다.
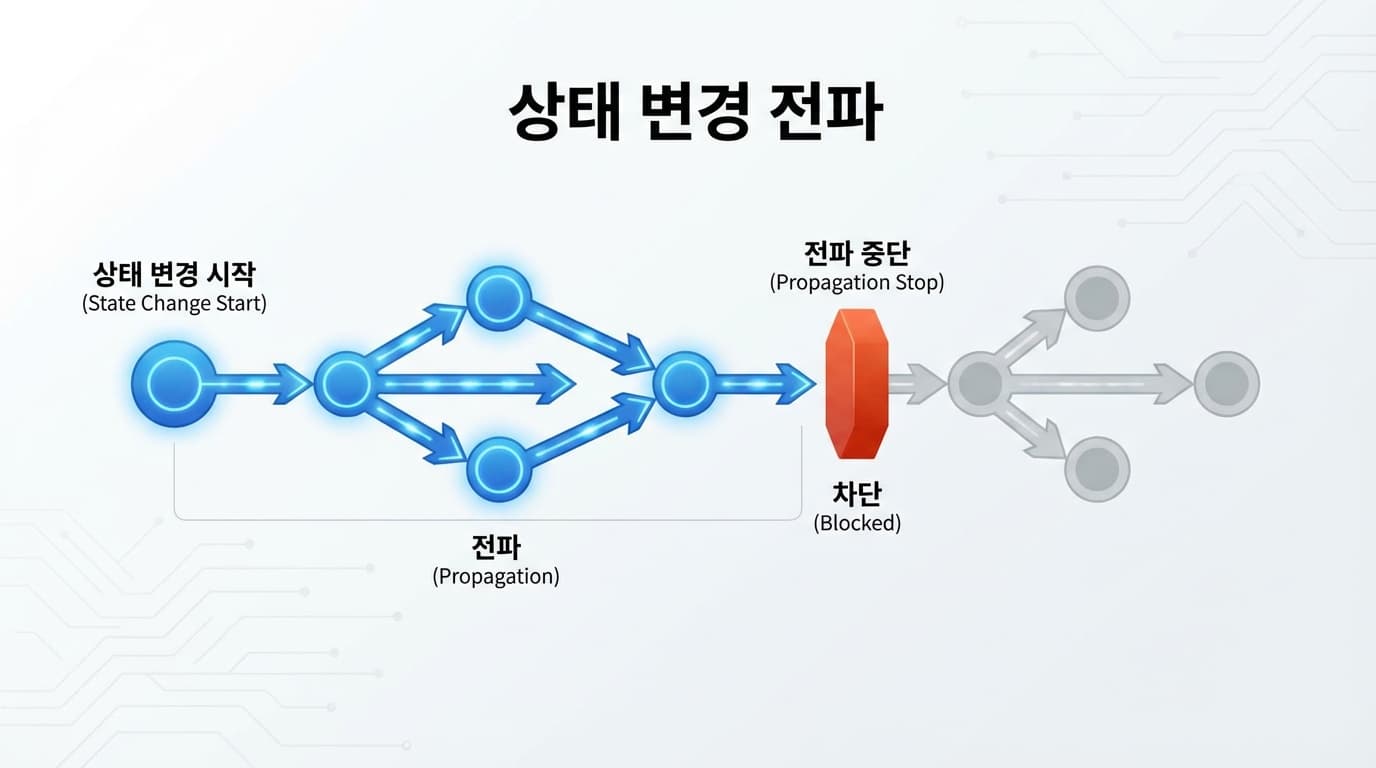
에디터는 변경된 줄부터 다음 줄로 넘어가며 상태를 재계산합니다.
그러다 어느 시점에서, 새로 계산한 상태가 기존에 캐싱해 둔 상태와 똑같아지는 순간이 옵니다.
예를 들어 */ (주석 끝)을 만나서 다시 일반 코드 상태로 돌아온 경우죠.
상태가 일치하는 순간, 에디터는 계산을 멈춥니다.
그 뒤로는 어차피 똑같을 테니까요.
이걸 수렴(Convergence)한다고 표현합니다.
덕분에 파일이 아무리 커도, 내가 수정한 부분과 그 영향이 미치는 범위까지만 계산하고 멈출 수 있는 겁니다.
마무리하며
이 기술은 xi-editor와 같은 고성능 에디터들이 수백 메가바이트짜리 파일을 다루면서도 깃털처럼 가볍게 동작하는 비결 중 하나입니다.
단순히 "빠르게 만든다"가 아니라,
- 배치 처리의 정확성
- 캐싱의 속도
- 메모리 효율
이 세 가지 사이에서 최적의 균형(Trade-off)을 찾아낸 결과죠.
우리 개발 업무도 비슷하지 않나요?
무조건 최신 기술, 무조건 빠른 속도보다는
현재 시스템의 제약 사항 안에서 가장 효율적인 '체크포인트'를 찾는 과정이 진짜 엔지니어링이 아닐까 싶습니다.
오늘 여러분의 코드는 어디쯤에서 '세이브' 되고 있나요?
한 번쯤 고민해 보는 하루가 되시길 바랍니다.



