
제목
네임드 빅테크 데이터 플랫폼 팀이 몰래 보는, 'SQL 완전 분해' 가이드 4단계
솔직히 고백하겠습니다.
스타트업에서 '야생형 개발자'로 구르던 시절, 저에게 SQL은 그저 '결과만 나오면 장땡'인 문자열이었습니다.
복잡한 서브 쿼리가 난무해도, EXPLAIN 떠서 인덱스만 잘 타면 "오케이, 배포하자!" 외치고 퇴근했죠.
그런데, 지금 회사로 이직하고 나서 뼈저리게 느꼈습니다.
대규모 트래픽과 수천 개의 테이블이 얽힌 이곳에서, 쿼리는 단순한 문자열이 아니라 '분석되어야 할 코드'였습니다.
입사 첫 주, 사내 데이터 플랫폼 팀이 쿼리를 자동으로 분석해 '데이터 리니지(Data Lineage)'를 그려내는 걸 보고 소름이 돋았습니다.
"이 테이블의 user_id가 어디서 와서 어디로 흘러가는지"를 귀신같이 추적하더군요.
그 비결이 바로 SQL 파서(SQL Parser)였습니다.
오늘은 제가 밤새워 뜯어보며 공부했던, 그리고 최근 화제가 된 'SQL 파서의 작동 원리'를 제 경험에 빗대어 풀어보려 합니다.
단순히 쿼리를 짜는 것을 넘어, '쿼리가 어떻게 이해되는지'를 알면 시야가 완전히 달라집니다.
1. 파싱의 시작: 렉서(Lexer), 의미 있는 조각 찾기
우리가 작성한 쿼리는 컴퓨터 입장에선 그저 긴 텍스트 덩어리일 뿐입니다.
가장 먼저 하는 일은 이 덩어리를 잘게 쪼개는 겁니다.
이걸 렉싱(Lexical Analysis)이라고 합니다.
SELECT * FROM users라는 문장이 있다면, 렉서(Lexer)는 이걸 이렇게 분해합니다.
Token(SELECT)
Token(*)
Token(FROM)
Token(IDENTIFIER, "users")
마치 우리가 영어 문장을 읽을 때 단어 단위로 끊어 읽는 것과 같습니다.
여기서 중요한 건 '방언(Dialect)' 처리입니다.
스타트업 시절, MySQL에서 PostgreSQL로 마이그레이션 하다가 식겁했던 기억이 납니다.
MySQL은 백틱(`)을 쓰는데, 표준 SQL이나 포스트그레스는 쌍따옴표(")를 쓰죠.
렉서는 아주 초기 단계에서 이런 '사투리'를 구분해서 토큰화합니다.
이 단계는 구조를 신경 쓰지 않습니다. 그냥 단어만 인식하는 '단순 노동'에 가깝습니다.
2. 파싱(Parser): 문법의 뼈대를 세우다
이제 진짜가 등장합니다.
쪼개진 토큰들을 가져와서 '문법적 구조'를 만드는 단계, 바로 파싱(Syntactic Analysis)입니다.
예를 들어 CREATE TABLE ... AS SELECT ...라는 문장이 들어오면, 파서는 미리 정의된 문법 규칙을 따릅니다.
"자, CREATE TABLE이 나왔으니 그다음엔 테이블 이름이 나와야 해."
"이름 확인했고, AS가 나왔으니 이제 SELECT 문이 시작되겠군."
마치 레고 블록을 설명서대로 조립하는 과정과 똑같습니다.
여기서 제가 예전에 정규표현식(RegEx)으로 쿼리 파싱하려다 대차게 삽질했던 기억이 납니다.
SELECT * FROM (SELECT ... ) 처럼 괄호가 중첩되면 정규식은 길을 잃습니다.
정규식은 '균형 잡힌 괄호'를 셀 수 없다는 수학적 한계가 있거든요.
파서는 이 중첩 구조를 완벽하게 이해하고 트리 구조로 만들어냅니다.
3. AST: 쿼리의 지도, 추상 구문 트리
파싱이 끝나면 AST(Abstract Syntax Tree)라는 결과물이 나옵니다.
이게 오늘 이야기의 핵심이자, 대기업 데이터 플랫폼의 심장입니다.
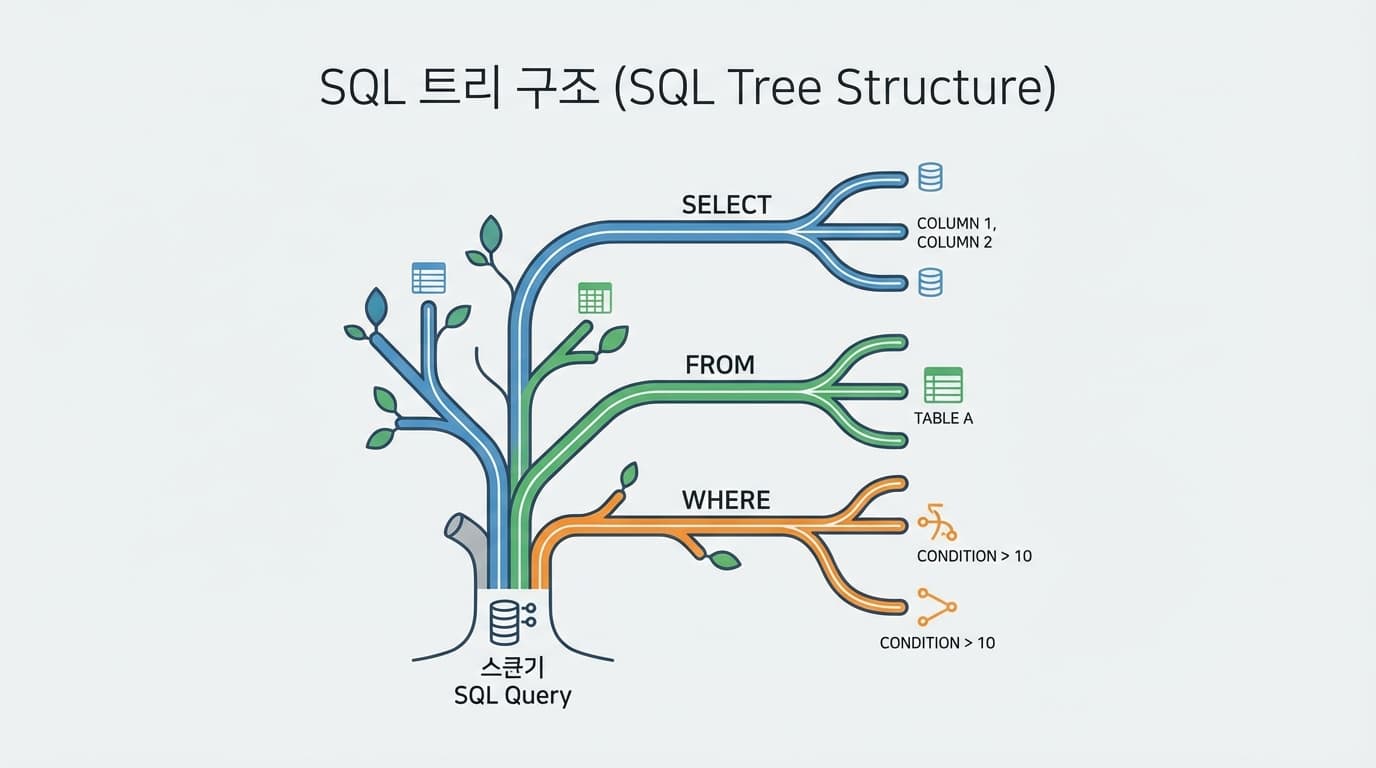
쿼리가 트리가 되면 우리는 엄청난 일을 할 수 있습니다.
- 트래버설(Traversal): 트리를 순회하며 특정 테이블이 쓰였는지 확인합니다.
- 트랜스폼(Transform):
WHERE절에 강제로 '삭제되지 않은 데이터(is_deleted = false)' 조건을 끼워 넣을 수 있습니다. - 트랜스파일(Transpile): Spark SQL을 Snowflake 문법으로 자동 변환합니다.
제가 충격받았던 '자동 리니지' 기능도 바로 이 AST를 분석해서 "이 컬럼이 저 테이블에서 왔구나"를 추적하는 것이었습니다.
4. 문법(Syntax) vs 의미(Semantics)
하지만 파서가 만능은 아닙니다.
파서는 '말이 되는지'만 봅니다. '사실인지'는 모릅니다.
SELECT name FROM ghosts
파서 입장에서는 완벽한 문장입니다. 문법적으로 틀린 게 없으니까요.
하지만 실제로 ghosts라는 테이블이 DB에 없다면? 쿼리는 실패합니다.
이걸 검증하는 게 의미 분석(Semantic Analysis)입니다.
스키마 정보(메타데이터)를 끌어와서 테이블 존재 여부, 컬럼 타입 일치 여부를 따지는 거죠.
저도 주니어 시절엔 "로컬에선 되는데 왜 운영에선 안 돼요?"라고 많이 물었습니다.
대부분 문법(Syntax)은 맞았지만, 환경별 스키마(Semantics)가 달라서 터진 문제였죠.
이제는 에러 로그만 봐도 "아, 이건 파서단 에러구나", "이건 시맨틱 에러구나" 감이 옵니다.
마무리하며
요즘 저는 Cursor나 Claude 같은 AI 도구를 적극적으로 씁니다.
재미있는 건, 이 글의 원작자도 Claude와 10시간 넘게 대화하며 개념을 정리했다고 하더군요.
복잡한 레거시 쿼리를 분석할 때, AI에게 "이거 AST 구조로 설명해 줘"라고 시켜보세요.
그냥 "해석해 줘"라고 할 때보다 훨씬 명확한 논리 구조를 보여줍니다.
기술의 깊이를 알면 도구를 더 잘 쓸 수 있습니다.
단순히 쿼리를 작성하는 '코더'에서, 데이터의 흐름과 구조를 설계하는 '엔지니어'로 성장하고 싶다면,
오늘 퇴근길에 여러분이 짠 쿼리가 어떻게 파싱되는지 한 번쯤 상상해 보시는 건 어떨까요?
8년 차가 되어서야 비로소 보이는 것들이, 여러분에겐 더 빨리 보였으면 좋겠습니다.


