
솔직히 말해봅시다.
우리는 주니어 시절부터 "Stateless(무상태)가 정답"이라고 세뇌당했습니다. 서버는 언제든 죽었다 살아나야 하고, 상태는 DB나 Redis에 몰아넣어야 한다고 배웠죠.
그게 마음 편하니까요. 개발하기도 쉽고.
그런데 트래픽이 터지고, 인프라 비용 청구서가 날아오고, 새벽 3시에 PagerDuty가 울리기 시작하면 깨닫게 됩니다.
Stateless는 '공짜'가 아닙니다.
엄청난 비용(Latency & Money)을 치르고 얻는 가짜 평화일 뿐입니다.
최근 데이터브릭스(Databricks)가 자신들의 오토 샤딩 시스템인 'Dicer'를 오픈소스로 풀면서 내놓은 기술 블로그를 뜯어봤습니다.
이 문서는 단순한 오픈소스 홍보가 아닙니다.
"우리가 Stateless로 버티다가 돈은 돈대로 쓰고 장애는 못 막아서 결국 이렇게 바꿨다"는 뼈저린 반성문이자, 생존 기록입니다.
실리콘밸리 빅테크들이 왜 결국엔 '상태(State)'를 다시 서버 안으로 가져오는지, 그 이유를 분석해 드립니다.
--> Stateless의 낭만과 현실
여러분의 서비스 아키텍처, 아마 이럴 겁니다.
WAS는 껍데기일 뿐이고, 모든 요청마다 DB를 찌르거나 Redis를 다녀옵니다.
[팩트] 데이터브릭스도 처음엔 그랬습니다.
하지만 그들이 겪은 현실은 이렇습니다.
- 네트워크 세금 (Network Tax) 아무리 Redis가 빨라도 네트워크 홉(Hop)은 물리적인 시간입니다. 모든 요청에 이 세금이 붙습니다.
- 직렬화/역직렬화 오버헤드 (CPU Burn) 객체를 꺼내서 JSON으로 바꾸고, 전송하고, 다시 객체로 바꾸는 과정. 여기서 CPU 사이클의 상당 부분이 증발합니다.
- Overread (과잉 읽기) 필요한 건 필드 하나인데, Redis에서는 거대 Blob 전체를 당겨옵니다. 대역폭 낭비, 메모리 낭비입니다.
결국 "Stateless해서 확장이 쉽다"는 말은, "돈으로 서버를 처바르면 확장이 된다"는 말과 동의어였습니다.
--> Redis는 만능열쇠가 아니다
그래서 시니어들은 생각합니다.
"데이터를 서버 메모리에 들고 있자(Caching). 그리고 샤딩(Sharding)하자."
여기서 보통 'Consistent Hashing(일관된 해싱)'을 꺼내 듭니다. 링(Ring) 구조 만들고 해시값으로 서버 분배하는 고전적인 수법이죠.
이론상 완벽해 보입니다.
하지만 제가 장담하는데, 이거 그대로 프로덕션에 올리면 여러분은 주말에 집에 못 갑니다.
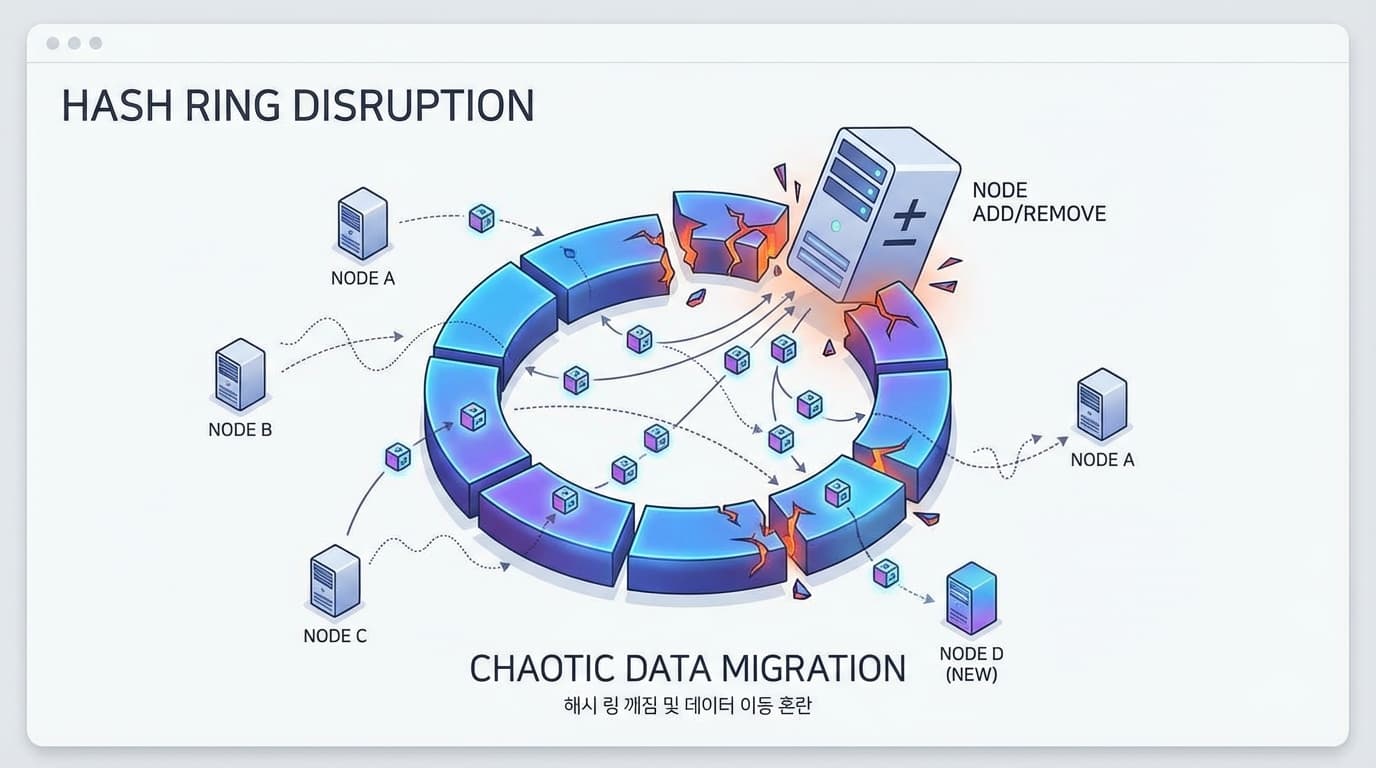
데이터브릭스가 겪은 문제도 똑같았습니다.
배포하려고 서버 한 대를 내리는 순간(Rolling Update), 혹은 오토스케일링으로 서버가 추가되는 순간.
그 짧은 찰나에 클라이언트들은 서로 다른 서버 뷰(View)를 가집니다.
누구는 A서버로 가고, 누구는 B서버로 갑니다.
Split-brain이 발생하고, 캐시 미스가 폭발하며, 백엔드 DB가 비명을 지릅니다.
이게 바로 '가용성 99.999%'를 외치던 시스템이 배포 때마다 5초씩 멈칫거리는 이유입니다.
--> Dicer: 그들이 찾은 해법 (Auto-Sharding)
데이터브릭스는 결국 'Dicer'라는 컨트롤 플레인을 만들었습니다.
핵심은 간단합니다. "운(Hash)에 맡기지 말고, 중앙에서 통제하자."
Dicer의 접근 방식은 우리에게 중요한 인사이트를 줍니다.
- Dense Cache (고밀도 캐시) 데이터를 로컬 메모리에 둡니다. 네트워크 홉도, 직렬화 비용도 없습니다.
- Zero-Downtime Migration 서버가 죽거나 재시작될 때, 샤드(Shard)의 이동을 중앙에서 통제합니다. 'Soft Leader Election' 같은 기법을 써서 서비스 중단 없이 소유권을 넘깁니다.
- 90% 이상의 캐시 적중률 이게 핵심입니다. 단순히 빠른 게 아니라, DB 부하를 극적으로 줄여줍니다. 비용 절감이 여기서 나옵니다.
[팩트] Unity Catalog나 SQL 오케스트레이션 엔진 같은 미션 크리티컬한 곳에 적용해서 성공했다고 합니다.
--> 엔지니어의 생존법
저는 기술의 우열을 논하고 싶은 게 아닙니다.
다만, "남들 다 하니까 Stateless", "책에서 봤으니까 Consistent Hashing"이라고 결정하는 태도가 위험하다는 겁니다.
여러분이 짠 코드가 새벽 3시에 여러분을 깨우지 않게 하려면, 시스템의 한계를 명확히 알아야 합니다.
트래픽이 적을 땐 Stateless가 맞습니다. 복잡도를 낮추는 게 최고니까요.
하지만 트래픽이 늘고 비용 압박이 들어오면, 결국 'Stateful'한 구조를 고민해야 할 시점이 옵니다.
그때 가서 맨땅에 헤딩하며 수동으로 샤딩 로직 짜지 마십시오.
데이터브릭스의 Dicer 같은 오픈소스나, 검증된 도구를 적극적으로 검토하세요.
시스템(System)으로 해결해야지, 사람의 '노력'이나 '운영'으로 해결하려 들면 안 됩니다.
우리의 목표는 화려한 아키텍처를 자랑하는 게 아닙니다.
시스템은 견고하게 돌려놓고, 정시에 퇴근해서 맥주 한 잔 마시는 것.
그게 진짜 엔지니어링입니다.



